tp-big-data-scala-spark-sansa
Atelier Big Data - 10 au 12 janvier 2023 - Hadoop/Spark/RDF
Objectifs
L’objectif de ce TP est d’intégrer puis d’utiliser des graphes de connaissances (fichier RDF) de plusieurs sources (Mesh, NCBI, FORUM) dans un DataLake et un environnement Spark/Hadoop.
Nous utiliserons des commandes Hadoop pour la gestion des fichiers et nous developperons le traitement en language scala.
Pour mettre au point la méthode nous utiliserons un spark-shell puis nous developperons une application spark pour automatiser le traitement.
Sujet
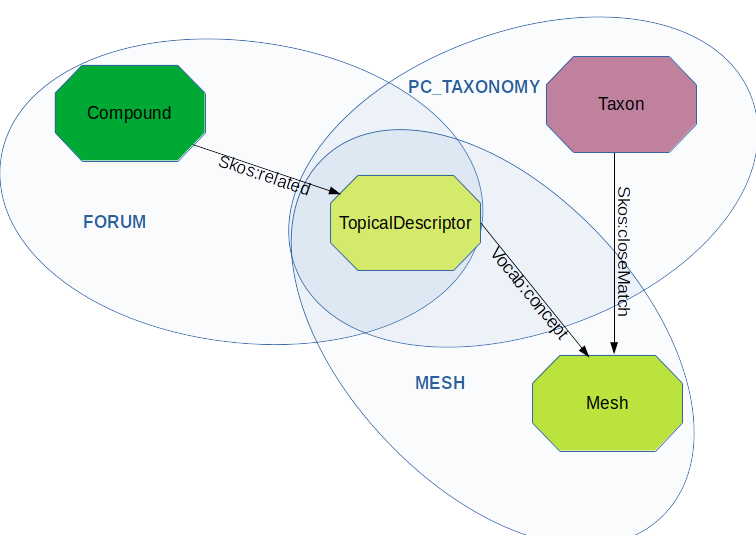
Associer un composé référencé dans le projet FORUM avec un PubChem/Taxonomy .
A - Utilisation d’un spark-shell pour travailler sur le jeu de données test
Il faut se référer à la partie “installation” si vous souhaitez travailler dans un environnement de développement personnel ou sur une machine virtuelle instanciée à partir d’un cloud académique (orion ou genostack par exemple).
Les plateformes d’exécution
Traitement sur un jeu de données test
Nous allons travailler a partir d’un jeu de données test qui se trouve dans rdf-files-test
Partie A - Manipulation des graphes RDF
I) Téléchargez le jeux de données puis transferez ces données sur le stockage HDFS
II) lancez un spark-shell en initialisant votre environnement avec la librairie Sansa
a) Utilisez la méthode find pour extraire le nombre de triplets contenant le prédicat “http://id.nlm.nih.gov/mesh/vocab#concept” sur le graphe mesh_test.nt.
b) Retrouvez cette information en utilisant statsPropertyUsage
c) En utilisant le package QualityAssessment, et les ressources (/rdf/mesh.nt.gz et /rdf/vocabulary_1.0.0.ttl), déterminez :
- Le ratio entre le nombre d’uri (sujet/predicat/objet) de type HashUri (contenant “#”) et le nombre de triplet (note: ne nécessite pas une recompilation de sansa)
Partie B - Appliquer une requête SPARQL sur plusieurs graphes RDF
I) Créer un RDD pour chaque graphe RDF
II) Fusionnez les RDD en un unique RDD
III) Appliquez la requete SPARQL suivante sur le RDD fusionné en utilisant net.sansa_stack.query.spark.sparqlify.QueryEngineFactorySparqlify et afficher le résultat
val query = """
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX meshv: <http://id.nlm.nih.gov/mesh/vocab#>
PREFIX chebi: <http://purl.obolibrary.org/obo/CHEBI_>
PREFIX mesh: <http://id.nlm.nih.gov/mesh/>
SELECT ?compound ?prop ?mesh ?taxon
WHERE {
?compound skos:related ?descriptor .
?descriptor ?prop ?mesh .
FILTER ( ?prop=meshv:concept || ?prop=meshv:preferredConcept )
?taxon skos:closeMatch ?mesh .
}
"""
IV) réitérez à partir de I) en utilisant des org.apache.spark.sql.Dataset et l’objet net.sansa_stack.ml.spark.featureExtraction.SparqlFrame de Sansa
V) Créez un fichier au format parquet ./results/compound_taxon.parquet .
VI) Combien de couples composé/taxon sont enregistrés ?
a) en utilisant une commande yarn
b) en utilisant un nouveau spark-shell
Part C - Intégration du code dans une application spark
I) Consultation des fichiers sources sur le cluster/datalake
a) Reperez les fichiers RDF sur le cluster avec les commandes yarn dans le repertoire /rdf/
b) Verifiez la structure des fichiers avec la command head de yarn
II) Récuperez l’archive du TP sur votre machine local ou sur le cluster du TP. l’archive template du tp .
a) inspectez le fichier ./build.sbt qui va permetre de compiler une archive jar pour deployer l’applicatif.
b) reperez le fichier contenat la class Main de l’application .
III) Intégrez dans la classe Main le traitement de la partie B.
IV) Assemblez le Jar de votre application en ciblant le jeu de donnée test et en utilisant la commande sbt assemby. Lancez le traitement.
V) Assemblez le Jar de votre application en ciblant le jeu de donnée du répertoire ./rdf. Lancez le traitement.
VI) Inspectez le resultat ./results/compound_taxon.parquet . Combien de couples composé/taxon sont enregistrés ?
VII) Visualisez le Spark History via un tunnel ssh
Liens
Commandes YARN
- Etat des workers :
yarn node -list -all - Process en cours :
yarn top - List des jobs :
yarn application -list - Log job :
yarn logs -applicationId application_<XXXX> - kill job :
yarn application -kill application_<XXXX> - Etat courant d’un job :
yarn app -status application_<XXXX> - Liste des noeuds utilisés :
yarn node -list,yarn node -list --showDetails - Taux d’utilisation du cluster :
yarn queue -status default